728x90
목차
1. Langchain(랭체인)이란?
- LLM(Large Language Model)을 실제 애플리케이션에 쉽게 연결하고 확장할 수 있도록 해주는 프레임워크
- 'Chain'이란? 여러 단계를 연결하는 것 (프롬프트 → LLM → 후처리 등)
- DocumentLoader, TextSplitter, Retriever 등을 조합하여 RAG 등을 구현할 수 있음
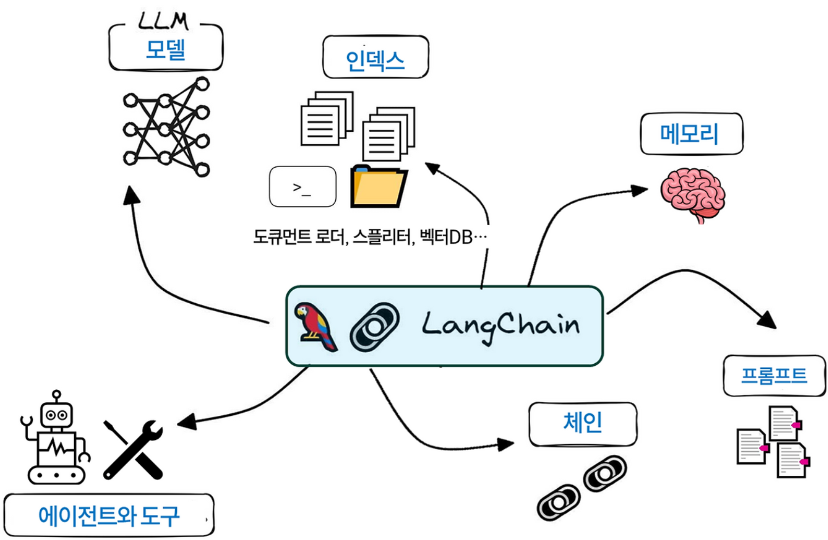
(출처: https://brunch.co.kr/@ywkim36/147)
Langchain의 핵심 모듈
| 이름 | 설명 |
| Prompt | LLM 입력을 구조화 - PromptTemplate: 변수 기반 프롬프트 템플릿 - ChatPromptTemplate: 다중 메시지(시스템/유저/AI) 기반 템플릿 ➡️동적으로 사용자 입력을 변수로 사용 가능 |
| LLM | 텍스트 생성 엔진(언어 모델) - 클래스: ChatOpenAI, ChatAnthropic, ChatGoogleGenerativeAI 등 - 파라미터(온도, 최대 토큰 수 등) 제어 가능 |
| Chains | 여러 단계를 묶은 실행 흐름 - LLMChain: Prompt + LLM + Output 처리 - SequentialChain: 여러 체인을 순서대로 실행 - RouterChain: 조건에 따라 다른 체인을 실행 |
| Agents | LLM이 상황에 따라 어떤 Tool을 사용할지 판단하고 실행 - Policy: 어떤 Tool을 언제 호출할지 결정(ReAct 패턴 등) |
| Tools | Agent가 쓰는 외부 기능 - 웹 검색(Tavily, DuckDuckGo), 계산기, 데이터베이스 조회, API 호출 등 |
| Memory | 대화/컨텍스트 저장 - ConversationBufferMemory: 그대로 기록 - ConversationSummaryMemory: 요약하여 기록 - VectorStoreRetrieverMemory: 임베딩 기반 검색 ➡️멀티턴 대화에서 맥락 유지에 필수 |
| Retrievers & Vectorstores | 검색 기반 RAG - Retrievers: 질의(query)에 맞는 문서를 찾아주는 모듈 - Vectorstores: 문서를 벡터 임베딩으로 저장/검색하는 저장소(Chroma, FAISS 등 지원) |
| Output Parsers | 결과물 구조화 - LLM의 자유로운 텍스트 출력을 원하는 형식(JSON, 리스트, 구조체)으로 변환 - StrOutputParser: 문자열 그대로 - JsonOutputParser: JSON 강제 변환 - PydanticOutputParser: Pydantic 모델 기반 구조화 |
2. Prompt Template
from langchain_core.prompts import PromptTemplate
template = "당신의 이름은 {name}이고, 직업은 {job}입니다. 자기소개를 해주세요."
prompt = PromptTemplate.from_template(template)- {name}, {job}: 변수를 위한 자리 표시자(placeholder)
- from_template: 자동으로 변수 이름을 추출해 input_variables를 생성
prompt.format(name="홍길동", job="개발자")출력:
당신의 이름은 홍길동이고, 직업은 개발자입니다. 자기소개를 해주세요.
Chat Prompt Template
- 대화형(Chat) 모델 전용 프롬프트
- ChatGPT와 같은 모델은 "역할(role) + 메시지(content)"와 같은 구조를 이해
- system: 모델의 성격, 규칙 설정
- user: 사용자 입력
- assistant: 이전 모델 응답(선택)
➡️ 단순 문자열 입력이 아닌, 리스트로 구조화된 입력을 만들 수 있도록 해주는 것이 Chat Prompt Template
from langchain_core.prompts import ChatPromptTemplate
# 대화형 프롬프트 템플릿 정의
chat_prompt = ChatPromptTemplate.from_messages([
("system", "당신은 친절한 한국어 선생님입니다."),
("user", "다음 문장을 영어로 번역해 주세요: {sentence}")
])
# 변수 채우기
final_prompt = chat_prompt.format_messages(sentence="오늘 날씨가 참 좋네요.")
print(final_prompt)실제 실행 예시 (Gemini API 연결)
import os
os.environ["GOOGLE_API_KEY"] = "API KEY 입력"
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
chat_prompt = ChatPromptTemplate.from_messages([
("system", "당신은 친절한 AI 자기소개 도우미입니다."),
("user", "이름: {name}, 직업: {job} → 자기소개를 작성해 주세요.")
])
# Gemini 모델 선택: "gemini-1.5-flash" (빠름/저렴) or "gemini-1.5-pro" (정확도↑)
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.7)
parser = StrOutputParser()
chain = chat_prompt | llm | parser
print(chain.invoke({"name": "홍길동", "job": "개발자"}))출력:
안녕하세요, 저는 홍길동입니다. 개발자로서 소프트웨어 개발에 대한 열정을 가지고 있습니다. (이후 경력이나 특정 분야, 혹은 강점을 추가하면 좋습니다. 예시는 아래와 같습니다.)
**예시 1 (경력 중심):** 저는 [경력기간] 동안 [업계/분야]에서 개발자로 일해 왔으며, [주요 프로젝트 또는 기술] 경험을 바탕으로 [자신의 강점 또는 성취]를 이루었습니다. 최근에는 [최근 프로젝트 또는 관심 분야]에 집중하고 있으며, 끊임없는 학습과 성장을 통해 더욱 발전된 개발자가 되기 위해 노력하고 있습니다.
**예시 2 (기술 중심):** 저는 [주요 사용 언어/기술]을 활용하여 [웹/모바일/데스크탑 등] 개발에 능숙합니다. 특히 [특정 기술 또는 분야]에 대한 전문성을 가지고 있으며, [구체적인 프로젝트 경험 또는 성과]를 통해 실력을 증명해왔습니다. 새로운 기술을 배우고 적용하는 것을 즐기며, 효율적이고 효과적인 코드 작성을 중요하게 생각합니다.
**예시 3 (개인적인 특성 강조):** 저는 문제 해결 능력이 뛰어나고, 꼼꼼하고 체계적인 개발 프로세스를 중요하게 생각합니다. 팀워크를 중시하며, 동료와의 협력을 통해 최고의 결과를 만들어내는 것을 목표로 합니다. 끊임없이 배우고 성장하며, 더 나은 개발자가 되기 위해 노력하는 열정적인 개발자입니다.
자신에게 맞는 예시를 선택하여 괄호 안에 구체적인 내용을 채워 넣으면 더욱 효과적인 자기소개가 될 것입니다. 어떤 자리에 자기소개를 할 것인지에 따라 내용을 조정하는 것도 중요합니다.
3. Chain 실행
- 단일 LLM 호출 체인: "Prompt → LLM → Parser (선택)" 의 직렬 파이프라인을 한 번 실행해 결과를 얻는 구조
| 단계 | 설명 |
| Prompt | 입력 변수를 끼워 넣어 LLM이 이해하기 쉬운 문자열을 만듦 |
| LLM | 한 번 호출(invoke)로 답변 생성 |
| Parser (선택) | LLM 출력을 문자열/JSON/스키마 등으로 확실한 타입으로 변환 |
➡️실행 흐름은 보통 prompt | llm | parser 형태의 파이프 연산으로 표현
import os
os.environ["GOOGLE_API_KEY"] = "API KEY 입력"
#from langchain_openai import ChatOpenAI
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 1) 프롬프트
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 간결하고 친절한 한국어 설명가입니다."),
("user", "주제: {topic}\n한 문단으로 핵심만 설명해 주세요.")
])
# 2) LLM (온도 낮게: 일관된 출력)
llm = ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.0)
# 3) 파서 (문자열 그대로 받기)
parser = StrOutputParser()
# 4) 단일 호출 체인
chain = prompt | llm | parser
# chain.invoke(input_dict): 단일 LLM 호출
print(chain.invoke({"topic": "강화학습"}))출력:
강화학습은 에이전트가 환경과 상호작용하며 보상을 최대화하는 방법을 학습하는 머신러닝 기법입니다. 에이전트는 시행착오를 통해 최적의 행동 전략을 찾아가며, 보상을 많이 받는 행동을 더 자주 선택하도록 학습합니다. 마치 사람이 훈련을 통해 특정 행동을 익히는 것과 유사합니다.
Few-Shot 예시 포함 단일 호출
fewshot = ChatPromptTemplate.from_messages([
("system", "당신은 용어를 비전문가에게 비유 중심으로 쉽게 설명합니다."),
("user", "용어: 오토리그레시브(autoregressive)"),
("assistant", "한 글자씩 이어 쓰는 시처럼, 이전 글을 바탕으로 다음 글자를 결정하는 방식입니다."),
("user", "용어: {term}")
])
(llm := ChatGoogleGenerativeAI(model="gemini-1.5-flash", temperature=0.7))
chain = fewshot | llm | StrOutputParser()
print(chain.invoke({"term": "어텐션(attention)"}))출력:
어텐션은 마치 사람이 책을 읽을 때처럼, 중요한 부분에 집중하는 능력이라고 생각하면 됩니다. 책 전체를 다 똑같이 보는 게 아니라, 현재 읽고 있는 문장을 이해하는 데 필요한 단어나 문장에 더 많은 '주의'를 기울이는 거죠. 컴퓨터도 마찬가지로, 많은 정보 중에서 현재 작업에 가장 중요한 정보에 집중해서 처리하는 기술이 어텐션입니다. 예를 들어, 번역을 할 때 어텐션은 문장의 특정 단어에 집중하여 번역의 정확도를 높입니다. 마치 중요한 단어에 형광펜을 긋고 읽는 것과 같다고 생각하면 쉬워요.
에러, 품질 체크 방법
- 온도(temperature): 0에 가까울 수록 일관성이 높고 창의력이 낮음
- 토큰 길이: max_tokens를 적절히 지정(너무 작으면 중간에 끊김)
- 가드레일: 스키마 파서, 예/아니오 등 제약 지시문을 프롬프트에 명확히 하기
- 디버그: print(prompt.format(...))로 실제 프롬프트 확인
➡️상태(State), 분기, 반복, 툴 호출 등 플로우 제어가 필요한 경우 LanGraph 사용
728x90
'공부 기록' 카테고리의 다른 글
| Langchain으로 AI Agent 만들기 (2) : Tool 연결하기 (1) | 2025.08.27 |
|---|
